Como hacer scraping con Python y Beautiful Soup
Beautiful Soup es una librería opensource de Python muy popular que se utiliza para el web scraping. La combinación del lenguaje Python con esta librería se convierte en una de las mejores herramienta para extraer información de páginas web.
En este artículo se pretende mejorar tus habilidades de web scraping utilizando la librería Beautiful Soup. A partir de ejercicios para principiantes usando la web que hemos preparado ParaScrapear.com. Te enseñaré cómo utilizar Python para rastrear la web y generar un CSV con los datos extraídos.

Conceptos básicos de un documento HTML
Antes de meternos de lleno en el código es muy importante entender como se estructura una página web. Por tanto entender las etiquetas de HTML es indispensable para saber recorrer un documento HTML y extraer la información que necesitamos.
Un ejemplo muy básico de página web sería:
<html>
<head>
<title>Scraping.link</title>
</head>
<body>
<h1 id="titulo">Scraping.link</h1>
<p class="parrafo">Bienvenido a tu primer scrapeo</p>
<body>
</html>
En este ejemplo mostramos las etiquetas HTML más habituales de una página web, que pasamos a detallar:
- Los documentos HTML están incluidos entre 2 etiquetas <html> y </html>
- Dentro de <head> se incluye el <title> que es lo que se muestra en la barra del navegador, las metas, estilos y javascript
- Dentro de la parte visible del HTML que vemos en el navegador se incluyen entre las etiquetas <body> y </body>
- El texto encabezado se usa la etiqueta <h1> que es el encabezado más grande hasta <h6>
- Los párrafos se definen con la etiqueta <p>
Como se puede ver todas las etiquetas tienes una apertura y un cierre. En algunos caso en la apertura se le pueden colocar atributos tales como id o class (nos ayudará al scrapeo), que se usan para dar formato con CSS e identificar estas partes desde JavaScript para trabajar con ellas.
Requisitos para comenzar
Vamos a utilizar 3 librerías de Python, que son:
- request, para realizar la petición HTTP y poder leer el documento HTML de una URL
- BeautifulSoup, para realizar las extracciones de las diferentes partes que nos interesan
- csv, para poder generar un fichero .csv con los datos extraídos
Por lo que vamos a utilizar el instalador de librerías de python que es pip
pip3 install requests
pip3 install beautifulsoup4
pip3 install csv
Vamos a pasar a realizar nuestro código para recorrer todas las frases sacando la categoría y el autor de la portada de ParaScrapear.com y lo vamos a guardar en un CSV
Comenzando tu primer script de scraping
Una vez que tenemos instalas estas 3 librerías vamos a crear nuestro script en un nuevo fichero que creemos con el nombre por ejemplo de scraping.py. Lo primero que haremos en este fichero es cargar las 3 librerías:
import requests
import csv
from bs4 import BeautifulSoup
A continuación vamos realizar una petición a la url https://parascrapear.com/ con la librería requests para traer todo su documento HTML que se queda guardado en la variable page.text, que es la entrada para parsear el documento HTML con BeautifulSoup en el siguiente código:
page = requests.get('https://parascrapear.com/')
soup = BeautifulSoup(page.text, 'html.parser')
Ahora necesitamos inspeccionar el documento HTML. Desde Chrome con pinchar en el segundo botón encima de la primera frase y darle a la opción «Inspeccionar» se nos abrirá lo que vemos en la siguiente captura. Como podemos ver cada frase está dentro de un blockquote y concretamente la frase la engloba una etiqueta <q> y </q>, para la categoría está en una etiqueta con class=»cat» y al autor le pasa lo mismo su etiqueta tiene la class=»author».
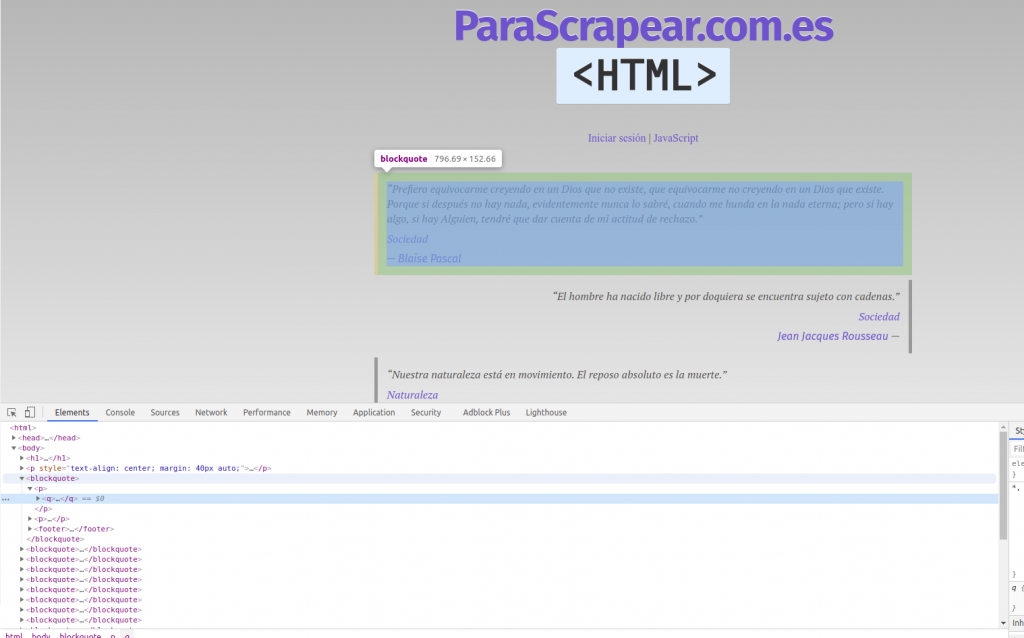
Por lo que vamos recorrer todos los blockquote y después dentro de cada uno extraer la frase, categoría y autor, como podemos ver en el siguiente código:
blockquote_items = soup.find_all('blockquote')
for blockquote in blockquote_items:
autor = blockquote.find(class_='author').text
categoria = blockquote.find(class_='cat').text
frase = blockquote.find('q').text
print([autor, categoria, frase])
Aquí está el código final con la escritura del resultado en el fichero CSV
import requests
import csv
from bs4 import BeautifulSoup
page = requests.get('https://parascrapear.com/')
soup = BeautifulSoup(page.text, 'html.parser')
f = csv.writer(open('frases.csv', 'w'))
f.writerow(['Autor', 'Categoria', 'Frase'])
blockquote_items = soup.find_all('blockquote')
for blockquote in blockquote_items:
autor = blockquote.find(class_='author').text
categoria = blockquote.find(class_='cat').text
frase = blockquote.find('q').text
f.writerow([autor, categoria, frase])
Ejemplos de códigos con BeautifulSoup
Aquí os dejo un listado de sencillos ejemplos de códigos usando BeautifulSoup:
- Buscar el siguiente hermano de una etiqueta
- Buscar etiquetas por clase CSS
- Cambiar el contenido de la etiqueta
- Construir con BeautifulSoup a partir de HTML
- Extraer las URLs de todos los enlaces
- Encontrar todas las etiquetas del documento HTML
- Construir un web scraper simple
- Encontrar el hermano anterior de una etiqueta
- Buscar el elemento anterior de una etiqueta
- Encontrar el siguiente elemento después de una etiqueta